Machine learning is a powerful tool that has transformed the way we approach complex problems in various industries. From image recognition to speech recognition, machine learning has helped us achieve breakthroughs that were once thought impossible, and it is approaching FAST, so maybe you might want to learn some of this stuff. With this post, I hope to help you understand some of the fundamentals of machine learning.
What Exactly Is Machine Learning Anyway?
Hey there, folks! If you're reading this, chances are you've heard of machine learning. But what exactly is it? Well, let me break it down for you. Machine learning is like teaching computers to learn and improve from experience, just like humans do. By giving the computer data and algorithms, it can recognize patterns and make predictions on its own, without being explicitly programmed. It's pretty cool stuff, and it's being used in all sorts of industries to help automate tasks and improve efficiency. So let's dive in!
The Fruit Problem
If you have any experience programming, think of how you would write some code to classify a given fruit. Let's say you want to tell the difference between an apple and an orange. You would write some rules to determine this. For example, you might notice that oranges are bumpy, orange in color, and mostly round. Apples, on the other hand, are red in color, smooth, and not mostly round. So, maybe your approach would be to analyze the number of green and orange pixels in a given image. If there are more orange than green pixels, then we assume that the given image of a fruit is orange. Sure, this approach might work for simple colored images, but what about images with a background? What if the image is black and white? What about images with no oranges or apples in them at all? What about an image of another fruit? As you can see, the real world is much more complicated, and your written rules will start to break down.
The Solution: Machine Learning
This is where machine learning and artificial intelligence (AI) can help us. We need an algorithm that can figure out the rules for us. What we need is a classifier. You can think of a classifier as a function that takes some input or feature and produces an output or label.
Now what is a feature exactly? Well you can think of features as basically pieces of information about something we want to classify. So in our example, we want to classify a fruit as either an orange or an apple. We might take the weight and texture of the fruit as features. These features can then be used to output a label about the fruit, which can be either an orange or apple in our example. Think of the label as the prediction our classifier makes about the given features. Look at the chart below to get a visual idea of what features and labels are in machine learning.

In machine learning, a "good" feature is a characteristic or attribute of the data that is relevant to the prediction task at hand. A good feature should capture important patterns and relationships in the data. Ideally, a good feature will be discriminative, meaning that it varies significantly between different classes, and invariant, meaning that it remains consistent even if the data is transformed. So for example, if you were trying to classify a dog's breed based on the feature of eye color, that wouldn't be very helpful for our classifier because a lot of dog breeds can have different eye colors. In other words, the feature of eye color is not very discriminative, so we won't be able to classify a given dog breed accurately.
So Now What?
So now that we have some training data and we know what features and labels are in machine learning, what do we do from this point? Well, I'm glad you asked. We can now move on to training our classifier with the training data. To do this, we can start off by installing the latest version of Python. Why Python? Because Python has tons of libraries and packages that can help us easily create machine learning classifiers. It is once of the most commonly used languages for machine learning.
Once you install Python, create a folder for where your project will live on your computer. For example, the path for my project is /Users/andre/Tutorials/Intro To ML.
Once you install Python, we need to create a virtual environment so that we can manage Python packages for our project without having to install these packages system-wide. To do this on Mac, we run the following command in our terminal:
python3 -m venv /path/to/project
For Windows, you can create a virtual environment for Python with the terminal command below:
c:\>c:\Python35\python -m venv c:\path\to\project
Once you create the virtual environment, you can activate it by using one of the commands below. Select the command that corresponds to your platform:

For example, for my project, I went ahead and used the command source /Users/andre/Tutorials/Intro\ To\ ML/bin/activate to activate my virtual environment since I have Z Shell.
Now that we have activated our virtual environment, let's install the scikit-learn Python package by using the command below (for Mac):
pip install -U numpy scipy scikit-learn
And for Windows:
pip install -U scikit-learn
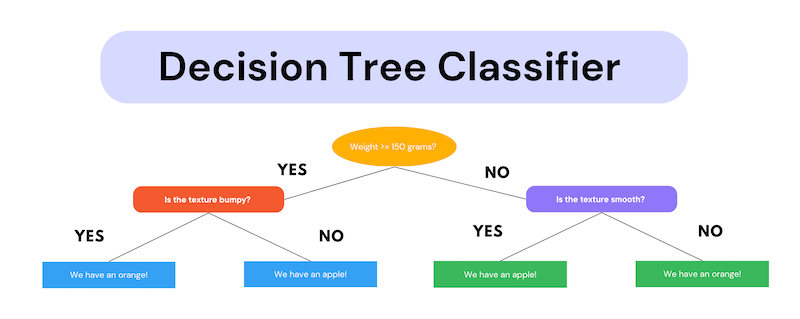
Great! We're ready to write our first machine learning program. Let's start off by importing a decision tree classifier from the module sklearn and defining our training data. You can think of a decision tree classifier as a box of rules for now. In one of my next posts, we'll dive into how the classifier works.
python from sklearn import tree features = [[140, 1], [130, 1], [150, 0], [170, 0]] labels = [0, 0, 1, 1]
In our labels list, 0 means the fruit is an apple, and 1 means it is an orange. Also, in our features array, each item in the array is an array of numbers. The first number in the array is the weight of the fruit, and the second number represents the texture of the fruit. We use 0 for a bumpy texture and 1 for a smooth texture. Let's finish writing our first machine learning program.
python from sklearn import tree features = [[140, 1], [130, 1], [150, 0], [170, 0]] labels = [0, 0, 1, 1] clf = tree.DecisionTreeClassifier() clf = clf.fit(features, labels) print(clf.predict([[160, 0]]))
On line 6, we instantiate our decision tree classifier. Moreover, on line 7, we call the method fit and insert our training data and labels as arguments. The fit method will find the patterns in our training data and come up with a box of rules that we can use to make predictions. Finally, on line 8, we call the predict method on an arbitrary piece of data. Keep in mind that this data was not in our training data, so this is something the classifier has never seen before. What do you think it will output for a label? Apple or orange? Well, the sample data is above 150 grams and the texture is bumpy. So this looks like an orange to me. Does our classifier agree? Run the program and find out!
>>> [1]
We get a [1], which means that the classifier has predicted that the given input of [160, 0] is an orange.
First Lesson Completed!
We've completed our first machine learning program and lesson. I'll be writing some more posts on machine learning, so look out for them! In the meantime, let me know if you have any questions. You can reach me through my contact form.